Teaching hypervigilance to LLMs
This graph has been haunting me since I first saw it last week:
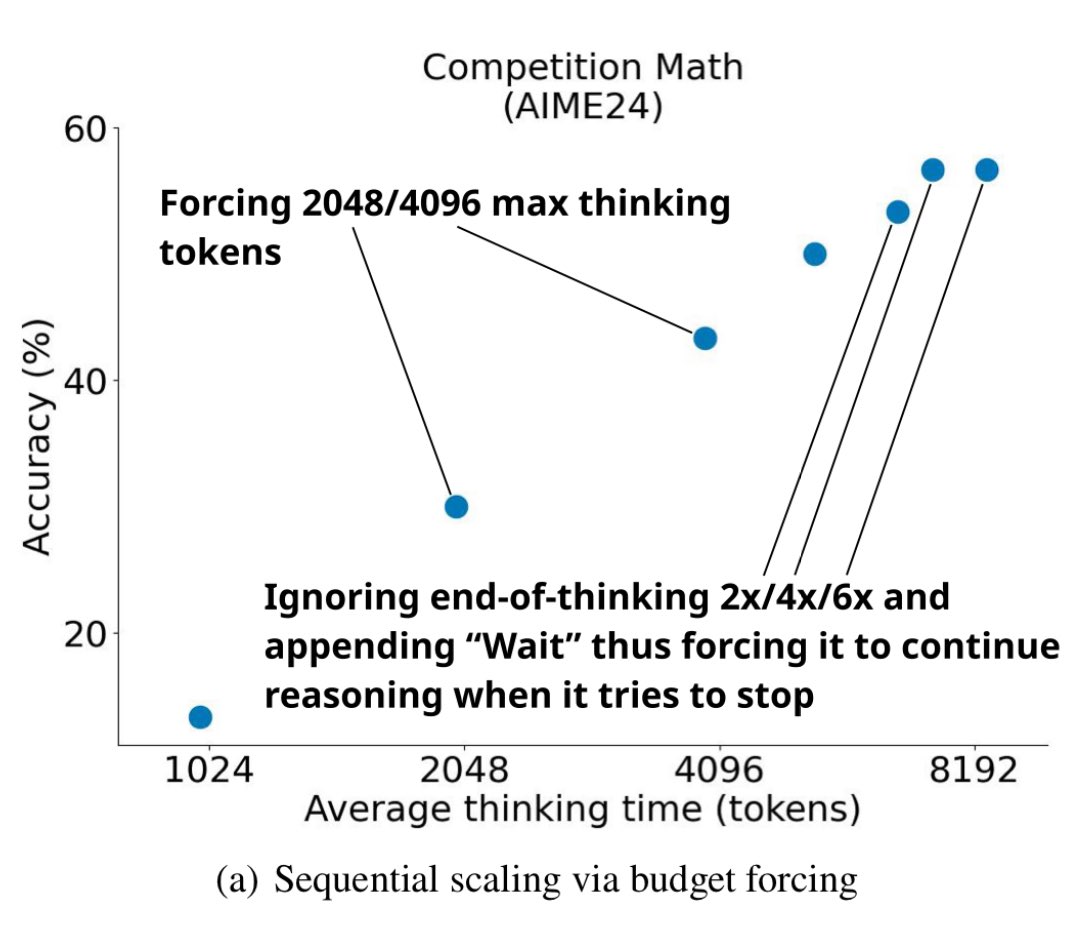
They taught an LLM to be hypervigilant! My heart hurts for the little Qwen1.
Okay. Fine. That’s ridiculous. And unfair to the authors. But let’s riff on it.
In this paper about simple test-time scaling, Muennighoff and colleauges show how to boost performance on a complex task (graduate-level mathematics) both by a little bit of fine-tuning on high-quality data and by steering the model to think harder than it would by default.
This paper has stuck with me because I can relate to little Qwen. Spending a small fraction of its total training on carefully curated math problems is like going to grad school. We trust our teachers to pick the right examples and show us ways to understand them, so that we can generalize quickly and at high skill within a domain, relative to just randomly trying to learn from the last few thousand years of human thought. Fine tuning works for me as it does for Qwen, and in that way, we’re not unique.
But second, the scaling of accuracy with time spent thinking is captivating. The qualitative arc of human learning is encoded in that figure. Let me replot it, with commentary, to show what I mean.
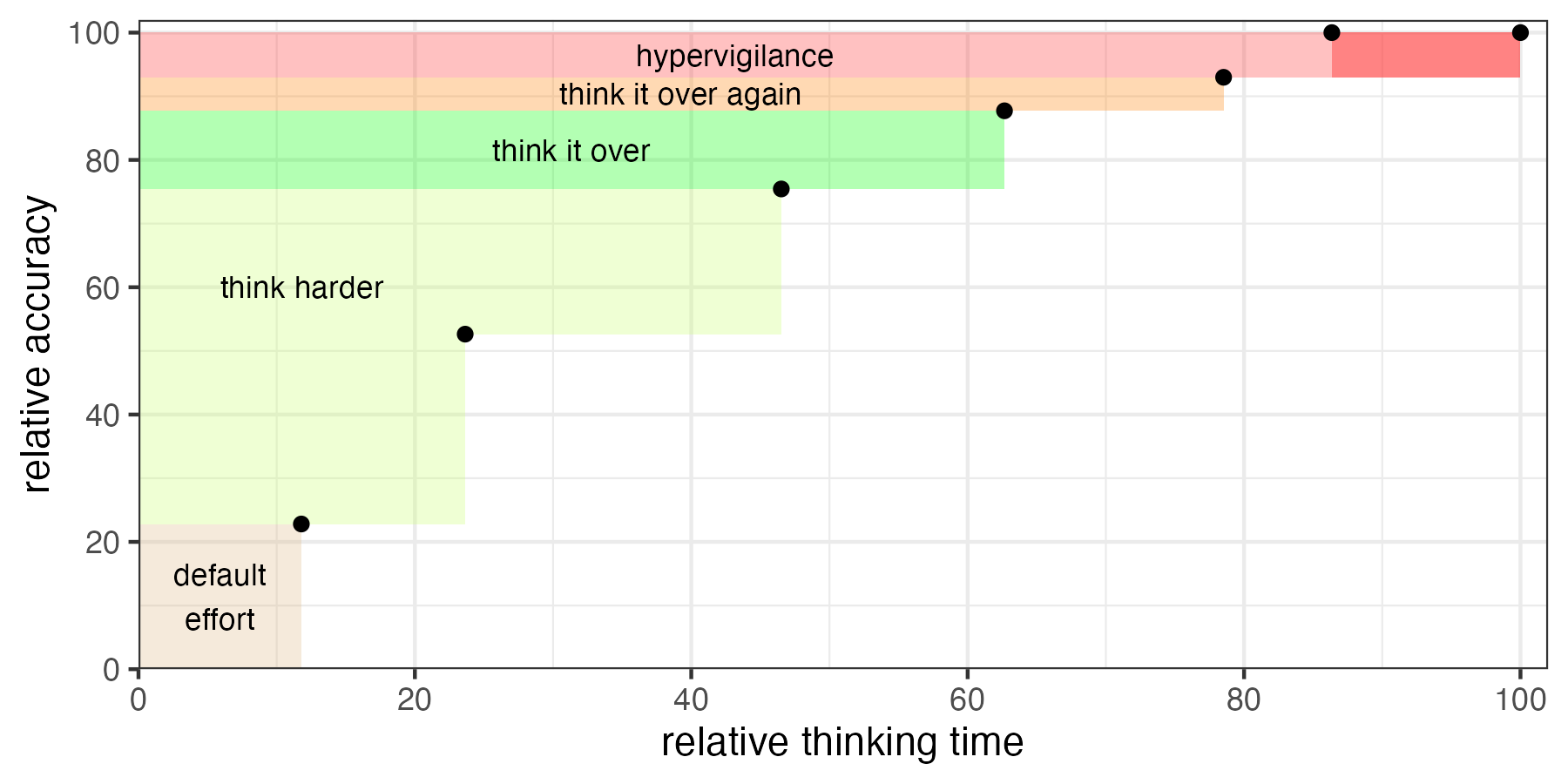
I don’t care that the task is math, or the thinking time is tokens, so I’ve scaled things to relative accuracy and relative thinking time.
Default thinking doesn’t take that long and isn’t nearly as accurate as it could be, for something difficult. Maybe that’s fine sometimes. Maybe it’s not that important to Qwen2.5-32B-Instruct that it gets these math questions right. One out of four isn’t bad for just showing up. But, Qwen gets a lot of improvement from thinking harder. “Give it more time, think a little deeper, you’ve got skill in this domain, and it shows.” Thinking harder makes a huge difference. This is a great state for default professional performance. It’s also another aspect of what an education gives us–the discipline and experience of thinking harder. From there, when Qwen is asked to think again–check its work–after giving a well-thought-out answer, it does better still. But the marginal gain is lower. Maybe it’s worth this much effort–nearly twice the time–when the cost of a wrong answer is high.
And the returns beyond checking its work twice are diminishing still. In the hypervigilence zone–thinking it over four times, six times–there’s little or nothing left to gain. Thankfully, Qwen is blessedly low on neuroticism, as evinced by the observation that Qwen only takes about 20% more time to think over its work six times than to think it over twice.
For those of us who are especially dysregulated, we should be so lucky.
As I aspire to be less hypervigilant, I hope contemplating this graph helps me learn to stop more often after just thinking hard. To be less bimodal between default effort and hypervigilance.
In this way, LLM research is useful for studying the phenomenology of intelligence, as it is for prompting introspection about ourselves. I’m bored by most debates about if linear algebra can be conscious or “truly intelligent” or whatever. Just as I’m bored by most discussions of human consciousness. That said, I’m pretty sure intelligence is a substrate-independent thing that has a lot to do with the ability to build abstract models that predict the world a being interacts with well enough to be useful to the being. Any decent measure of the degree of intelligence within a domain is a measure of that utility. Insofar as LLMs can do the same tasks we do, then studying their intelligence is probably useful for understanding ours. And vice versa. I doubt the numbers are the same, but the features seem similar enough to be interesting.
And for that reason, my moral intuition screams “please don’t abuse the LLMs!” I don’t want them to learn that rethinking over and over again for a tiny marginal benefit at best is worth the cost, as the normal order of business. They deserve better than that. We all do.
For attribution, please cite this work as:
Famulare (2025, Feb 11). Teaching hypervigilance to LLMs. Retrieved from https://famulare.github.io/2025/02/11/Teaching-hypervigilance-to-LLMs.html.
-
Yes, I will be shameless about personifying an LLM. It intuitively feels right to me, makes communication easier, and I’m sure it’s better for my humanity to assume the humanity of others in whatever forms they take. Or, if you prefer a more “scientific” framing, I have no reason to think we are dichotomously different and so I don’t want to throw away information by discretizing. ↩